
数据库复习(mysql)
数据库概述
为什么要使用数据库
- 横向:存储数据量大
相比保存在文件里,使用时需要遍历,效率更高,而且有很多的优化方法 - 纵向:数据的丰富度
存储的数据类型可以多种多样 - 持久化
能将瞬时数据(比如内存中的数据,是不能永久保存的)持久化为持久数据(比如持久化至数据库中,能够长久保存)。关闭应用然后重新启动则先前的数据依然存在。
关闭系统(电脑)然后重新启动则先前的数据依然存在。
RDBMS 与 非RDBMS
关系型数据库(RDBMS)
关系型数据库模型是把复杂的数据结构归结为简单的
二元关系 (即二维表格形式)。
非关系型数据库(非RDBMS)
非关系型数据库,可看成传统关系型数据库的功能 阉割版本 ,基于键值对存储数据,不需要经过SQL层的解析, 性能非常高 。同时,通过减少不常用的功能,进一步提高性能。
键值型数据库
通过 Key-Value 键值的方式来存储数据。
Key 作为唯一的标识符,优点是查找速度快,在这方面明显优于关系型数据库,
缺点是无法像关系型数据库一样使用条件过滤(比如 WHERE),如果你不知道去哪里找数据,就要遍历所有的键,
这就会消耗大量的计算。
键值型数据库典型的使用场景是作为 内存缓存 。Redis是最流行的键值型数据库。文档型数据库
可存放并获取文档,可以是XML、JSON等格式。在数据库中文档作为处理信息的基本单位,一个文档就相当于一条记录。文档数据库所存放的文档,就相当于键值数据库所存放的“值”。
MongoDB是最流行的文档型数据库。此外,还有CouchDB等。搜索引擎数据库
虽然关系型数据库采用了索引提升检索效率,但是针对全文索引效率却较低。
搜索引擎数据库是应用在搜索引擎领域的数据存储形式,由于搜索引擎会爬取大量的数据,并以特定的格式进行存储,这样在检索的时候才能保证性能最优。核心原理是“倒排索引”。
典型产品:Solr、Elasticsearch、Splunk 等。列式数据库
列式数据库是相对于行式存储的数据库,Oracle、MySQL、SQL Server 等数据库都是采用的行式存储(Row-based),而列式数据库是将数据按照列存储到数据库中,这样做的好处是可以大量降低系统的I/O,适合于分布式文件系统,不足在于功能相对有限。
典型产品:HBase等。图形数据库
一种存储图形关系的数据库。它利用了图这种数据结构存储了实体(对象)
之间的关系。
关系型数据用于存储明确关系的数据,但对于复杂关系的数据存储却有些力不从心。如社交网络中人物之间的关系,如果用关系型数据库则非常复杂,用图形数据库将非常简单。
典型产品:Neo4J、InfoGrid等。
NoSQL即非关系型数据库。NoSQL 对 SQL 做出了很好的补充,比如实际开发中,有很多业务需求,其实并不需要完整的关系型数据库功能,非关系型数据库的功能就足够使用了。这种情况下,使用 性能更高 、 成本更低 的非关系型数据库当然是更明智的选择。比如:日志收集、排行榜、定时器等。
基本的SELECT语句
SQL 分类
SQL语言在功能上主要分为如下3大类:
- DDL(Data Definition Languages、数据定义语言),这些语句定义了不同的数据库、表、视图、索引等数据库对象,还可以用来创建、删除、修改数据库和数据表的结构。
主要的语句关键字包括 CREATE 、 DROP 、 ALTER 等。
- DML(Data Manipulation Language、数据操作语言),用于添加、删除、更新和查询数据库记录,并检查数据完整性。
主要的语句关键字包括 INSERT 、 DELETE 、 UPDATE 、 SELECT 等。
SELECT是SQL语言的基础,最为重要。 - DCL(Data Control Language、数据控制语言),用于定义数据库、表、字段、用户的访问权限和安全级别。
主要的语句关键字包括 GRANT 、 REVOKE 、 COMMIT 、 ROLLBACK 、 SAVEPOINT 等。
SQL语言的规则与规范
- SQL 可以写在一行或者多行。为了提高可读性,各子句分行写,必要时使用缩进
- 每条命令以 ; 或 \g 或 \G 结束
- 关键字不能被缩写也不能分行
- 关于标点符号
- 字符串型和日期时间类型的数据可以使用单引号(’ ‘)表示
- 列的别名,尽量使用双引号(” “),而且不建议省略as
1 | #以下两句是一样的,不区分大小写 |
SQL大小写规范
- MySQL 在 Windows 环境下是大小写不敏感的
- MySQL 在 Linux 环境下是大小写敏感的
- 数据库名、表名、表的别名、变量名是严格区分大小写的
- 关键字、函数名、列名(或字段名)、列的别名(字段的别名) 是忽略大小写的
推荐采用统一的书写规范:
- 数据库名、表名、表别名、字段名、字段别名等都小写
- SQL 关键字、函数名、绑定变量等都大写
注释
可以使用如下格式的注释结构
1 | 单行注释:#注释文字(MySQL特有的方式) |
数据导入指令
在命令行客户端登录mysql,使用source指令导入
1 | source d:\mysqldb.sql |
1 | mysql> desc employees; |
基本的SELECT语句
SELECT … FROM
在生产环境下,不推荐直接使用 SELECT * 进行查询。
选择特定的列:
1 | SELECT department_id, location_id |
列的别名
在列名和别名之间加入关键字AS,AS可以省略,别名建议使用双引号,以便在别名中包含空格或特
殊的字符并区分大小写。
1 | SELECT last_name "Name", salary*12 "Annual Salary" |
去除重复行
默认情况下,查询会返回全部行,包括重复行。
在SELECT语句中使用关键字DISTINCT去除重复行
1 | SELECT DISTINCT department_id,salary |
- DISTINCT 需要放到所有列名的前面,如果写成 SELECT salary, DISTINCT department_id
FROM employees 会报错。- DISTINCT 是对后面所有列名的组合进行去重。如果想要看都有哪些不同的部门(department_id),只需
要写 DISTINCT department_id 即可,后面不需要再加其他的列名了。
空值参与运算
所有运算符或列值遇到null值,运算的结果都为null。
在 MySQL 里面, 空值不等于空字符串。一个空字符串的长度是 0,而一个空值的长度是空。而且,在 MySQL 里面,空值是占用空间的。
着重号
保证表中的字段、表名等没有和保留字、数据库系统或常用方法冲突。
如果真的相同,请在
SQL语句中使用一对``(着重号)引起来。
1 | mysql> SELECT * FROM ORDER; #错误 |
查询常数
SELECT 查询还可以对常数进行查询。
就是在 SELECT 查询结果中增加一列固定的常数列。这列的取值是我们指定的,而不是从数据表中动态取出的。
比如说,我们想对 employees 数据表中的员工姓名进行查询,同时增加一列字段 corporation ,这个
字段固定值为“尚硅谷”,可以这样写:
1 | SELECT '尚硅谷' as corporation, last_name FROM employees; |
然后查询结果会出现两列,一列corporation,值全是尚硅谷,一列是所有的last_name
不过只是创建一个临时的列corporation,只在查询结果中存在,不会影响原始的employees表结构。
显示表结构
使用DESCRIBE 或 DESC 命令,表示表结构。
1 | DESCRIBE employees; |
1 | mysql> desc employees; |
其中,各个字段的含义分别解释如下:
- Field:表示字段名称。
- Type:表示字段类型,这里 barcode、goodsname 是文本型的,price 是整数类型的。
- Null:表示该列是否可以存储NULL值。
- Key:表示该列是否已编制索引。PRI表示该列是表主键的一部分;UNI表示该列是UNIQUE索引的一
部分;MUL表示在列中某个给定值允许出现多次。 - Default:表示该列是否有默认值,如果有,那么值是多少。
- Extra:表示可以获取的与给定列有关的附加信息,例如AUTO_INCREMENT等。
过滤数据
使用WHERE 子句,将不满足条件的行过滤掉
1 | SELECT employee_id, last_name, job_id, department_id |
运算符
算术运算符
对数值或表达式进行加(+)、减(-)、乘(*)、除(/)和取模(%)运算。
加法与减法运算符
1 | mysql> SELECT 100, 100 + 0, 100 - 0, 100 + 50, 100 + 50 -30, 100 + 35.5, 100 - 35.5 |
- 一个整数类型的值对整数进行加法和减法操作,结果还是一个整数;
- 一个整数类型的值对浮点数进行加法和减法操作,结果是一个浮点数;
- 在Java中,+的左右两边如果有字符串,那么表示字符串的拼接。但是在MySQL中+只表示数值相加。如果遇到非数值类型,先尝试转成数值,如果转失败,就按0计算。(补充:MySQL中字符串拼接要使用字符串函数CONCAT()实现)
乘法与除法运算符
1 | mysql> SELECT 100, 100 * 1, 100 * 1.0, 100 / 1.0, 100 / 2,100 + 2 * 5 / 2,100 /3, 100 |
- 一个数乘以浮点数1和除以浮点数1后变成浮点数,数值与原数相等;
- 一个数除以整数后,不管是否能除尽,结果都为一个浮点数;
- 一个数除以另一个数,除不尽时,结果为一个浮点数,并保留到小数点后4位;
- 在MySQL中,一个数除以0为NULL。
求模(求余)运算符
1 | mysql> SELECT 12 % 3, 12 MOD 5 FROM dual; |
比较运算符
比较运算符用来对表达式左边的操作数和右边的操作数进行比较,比较的结果为真则返回1,比较的结果
为假则返回0,其他情况则返回NULL。
比较运算符经常被用来作为SELECT查询语句的条件来使用,返回符合条件的结果记录。
等号运算符
等号运算符(=)判断等号两边的值、字符串或表达式是否相等,如果相等则返回1,不相等则返回
0。
在使用等号运算符时,遵循如下规则:
- 如果等号两边都为字符串,则MySQL会按照字符串进行比较,其比较的是每个字符串中字符的ANSI编码是否相等。
- 如果等号两边一个是整数,另一个是字符串,则MySQL会将字符串转化为数字进行比较。
- 如果等号两边中有一个为NULL,则比较结果为NULL。
1 | mysql> SELECT 1 = 2, 0 = 'abc', 1 = 'abc', '' = NULL , NULL = NULL; |
1 | #查询salary=10000,注意在Java中比较是== |
安全等于运算符
安全等于运算符(<=>)与等于运算符(=)的作用是相似的, 唯一的区别 是‘<=>’可以用来对NULL进行判断。
在两个操作数均为NULL时,其返回值为1,而不为NULL;
当一个操作数为NULL时,其返回值为0,而不为NULL。
不等于运算符
不等于运算符(<>和!=)用于判断两边的数字、字符串或者表达式的值是否不相等,如果不相等则返回1,相等则返回0。
不等于运算符不能判断NULL值。如果两边的值有任意一个为NULL,或两边都为NULL,则结果为NULL。
1 | mysql> SELECT 1 <> 1, 1 != 2, 'a' != 'b', (3+4) <> (2+6), 'a' != NULL, NULL <> NULL; |
非符号类型的运算符
非符号类型的运算符:
空运算符
空运算符(IS NULL或者ISNULL)判断一个值是否为NULL,如果为NULL则返回1,否则返回0。 SQL语句示例如下:
1 | mysql> SELECT NULL IS NULL, ISNULL(NULL), ISNULL('a'), 1 IS NULL; |
1 | #查询commission_pct等于NULL。比较如下的四种写法 |
非空运算符
非空运算符(IS NOT NULL)判断一个值是否不为NULL,如果不为NULL则返回1,否则返
回0。 SQL语句示例如下:
1 | mysql> SELECT NULL IS NOT NULL, 'a' IS NOT NULL, 1 IS NOT NULL; |
1 | #查询commission_pct不等于NULL |
最小值运算符
语法格式为:LEAST(值1,值2,…,值n)。其中,“值n”表示参数列表中有n个值。在有两个或多个参数的情况下,返回最小值。
1 | mysql> SELECT LEAST (1,0,2), LEAST('b','a','c'), LEAST(1,NULL,2); |
- 当参数是整数或者浮点数时,LEAST将返回其中最小的值;
- 当参数为字符串时,返回字母表中顺序最靠前的字符;
- 当比较值列表中有NULL时,不能判断大小,返回值为NULL。
最大值运算符
语法格式为:GREATEST(值1,值2,…,值n)。其中,n表示参数列表中有n个值。当有两个或多个参数时,返回值为最大值。假如任意一个自变量为NULL,则GREATEST()的返回值为NULL。
1 | mysql> SELECT GREATEST(1,0,2), GREATEST('b','a','c'), GREATEST(1,NULL,2); |
- 当参数中是整数或者浮点数时,GREATEST将返回其中最大的值;
- 当参数为字符串时,返回字母表中顺序最靠后的字符;
- 当比较值列表中有NULL时,不能判断大小,返回值为NULL。
BETWEEN AND运算符
BETWEEN运算符使用的格式通常为SELECT D FROM TABLE WHERE C BETWEEN AAND B,此时,当C大于或等于A,并且C小于或等于B时,结果为1,否则结果为0。
1 | mysql> SELECT 1 BETWEEN 0 AND 1, 10 BETWEEN 11 AND 12, 'b' BETWEEN 'a' AND 'c'; |
1 | SELECT last_name, salary |
IN运算符
IN运算符用于判断给定的值是否是IN列表中的一个值,如果是则返回1,否则返回0。如果给定的值为NULL,或者IN列表中存在NULL,则结果为NULL。
1 | mysql> SELECT 'a' IN ('a','b','c'), 1 IN (2,3), NULL IN ('a','b'), 'a' IN ('a', NULL); |
1 | SELECT employee_id, last_name, salary, manager_id |
NOT IN运算符
NOT IN运算符用于判断给定的值是否不是IN列表中的一个值,如果不是IN列表中的一个值,则返回1,否则返回0。
1 | mysql> SELECT 'a' NOT IN ('a','b','c'), 1 NOT IN (2,3); |
LIKE运算符
LIKE运算符主要用来匹配字符串,通常用于模糊匹配,如果满足条件则返回1,否则返回0。如果给定的值或者匹配条件为NULL,则返回结果为NULL。
LIKE运算符通常使用如下通配符:
- %:匹配0个或多个字符
- _:只能匹配一个字符
SQL语句示例如下:
1 | mysql> SELECT NULL LIKE 'abc', 'abc' LIKE NULL; |
1 | SELECT first_name |
1 | SELECT last_name |
转义字符
1 | SELECT job_id |
ESCAPE
另一种写法:
1 | SELECT job_id |
REGEXP运算符(正则表达式)
REGEXP运算符用来匹配字符串,语法格式为: expr REGEXP 匹配条件。
- 如果expr满足匹配条件,返回1;
- 如果不满足,则返回0。
- 若expr或匹配条件任意一个为NULL,则结果为NULL。
REGEXP运算符在进行匹配时,常用的有下面几种通配符:

查询以特定字符或字符串开头的记录
字符‘^’匹配以特定字符或者字符串开头的文本。
在fruits表中,查询f_name字段以字母‘b’开头的记录,SQL语句如下:1
mysql> SELECT * FROM fruits WHERE f_name REGEXP '^b';
查询以特定字符或字符串结尾的记录
字符‘$’匹配以特定字符或者字符串结尾的文本。
在fruits表中,查询f_name字段以字母‘y’结尾的记录,SQL语句如下:1
mysql> SELECT * FROM fruits WHERE f_name REGEXP 'y$';
用符号”.”来替代字符串中的任意一个字符
字符‘.’匹配任意一个字符。
查询f_name字段值包含字母‘a’与‘g’且两个字母之间只有一个字母的记录,SQL语句如下:1
mysql> SELECT * FROM fruits WHERE f_name REGEXP 'a.g';
使用”*”和”+”来匹配多个字符
星号*匹配前面的字符任意多次,包括0次。加号‘+’匹配前面的字符至少一次。
在fruits表中,查询f_name字段值以字母‘b’开头且‘b’后面出现字母‘a’的记录,SQL语句如下:1
mysql> SELECT * FROM fruits WHERE f_name REGEXP '^ba*';
在fruits表中,查询f_name字段值以字母‘b’开头且‘b’后面出现字母‘a’至少一次的记录,SQL语句如下:
1
mysql> SELECT * FROM fruits WHERE f_name REGEXP '^ba+
匹配指定字符串
正则表达式可以匹配指定字符串,只要这个字符串在查询文本中即可,如要匹配多个字符串,多个字符串之间使用分隔符‘|’隔开。
在fruits表中,查询f_name字段值包含字符串“on”的记录,SQL语句如下:1
mysql> SELECT * FROM fruits WHERE f_name REGEXP 'on';
在fruits表中,查询f_name字段值包含字符串“on”或者“ap”的记录,SQL语句如下:
1
mysql> SELECT * FROM fruits WHERE f_name REGEXP 'on|ap'
匹配指定字符中的任意一个
方括号“[]”指定一个字符集合,只匹配其中任何一个字符,即为所查找的文本。
在fruits表中,查找f_name字段中包含字母‘o’或者‘t’的记录,SQL语句如下:1
mysql> SELECT * FROM fruits WHERE f_name REGEXP '[ot]';
在fruits表中,查询s_id字段中包含4、5或者6的记录,SQL语句如下:
1
mysql> SELECT * FROM fruits WHERE s_id REGEXP '[456]';
匹配指定字符以外的字符
“[^字符集合]” 匹配不在指定集合中的任何字符。
在fruits表中,查询f_id字段中包含字母ae和数字12以外字符的记录,SQL语句如下:1
mysql> SELECT * FROM fruits WHERE f_id REGEXP '[^a-e1-2]';
使用{n,}或者{n,m}来指定字符串连续出现的次数
“字符串{n,}”表示至少匹配n次前面的字符;“字符串{n,m}”表示匹配前面的字符串不少于n次,不多于m次。例如,a{2,}表示字母a连续出现至少2次,也可以大于2次;a{2,4}表示字母a连续出现最少2次,最多不能超过4次。
在fruits表中,查询f_name字段值出现字母‘x’至少2次的记录,SQL语句如下:1
mysql> SELECT * FROM fruits WHERE f_name REGEXP 'x{2,}';
在fruits表中,查询f_name字段值出现字符串“ba”最少1次、最多3次的记录,SQL语句如下:
1
mysql> SELECT * FROM fruits WHERE f_name REGEXP 'ba{1,3}';
逻辑运算符
逻辑运算符主要用来判断表达式的真假,在MySQL中,逻辑运算符的返回结果为1、0或者NULL。
逻辑非运算符
逻辑非(NOT或!)运算符表示
- 当给定的值为0时返回1;
- 当给定的值为非0值时返回0;
- 当给定的值为NULL时,返回NULL。
1 | mysql> SELECT NOT 1, NOT 0, NOT(1+1), NOT !1, NOT NULL; |
1 | SELECT last_name, job_id |
逻辑与运算符
逻辑与(AND或&&)运算符是
- 当给定的所有值均为非0值,并且都不为NULL时,返回1;
- 当给定的一个值或者多个值为0时则返回0;
- 否则返回NULL。
1
2
3
4
5
6
7mysql> SELECT 1 AND -1, 0 AND 1, 0 AND NULL, 1 AND NULL;
+----------+---------+------------+------------+
| 1 AND -1 | 0 AND 1 | 0 AND NULL | 1 AND NULL |
+----------+---------+------------+------------+
| 1 | 0 | 0 | NULL |
+----------+---------+------------+------------+
1 row in set (0.00 sec)1
2
3
4SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary >=10000
AND job_id LIKE '%MAN%';
逻辑或运算符
逻辑或(OR或||)运算符是
- 当给定的值都不为NULL,并且任何一个值为非0值时,则返回1,否则返回0;
- 当一个值为NULL,并且另一个值为非0值时,返回1,否则返回NULL;
- 当两个值都为NULL时,返回NULL。
1
2
3
4
5
6
7mysql> SELECT 1 OR -1, 1 OR 0, 1 OR NULL, 0 || NULL, NULL || NULL;
+---------+--------+-----------+-----------+--------------+
| 1 OR -1 | 1 OR 0 | 1 OR NULL | 0 || NULL | NULL || NULL |
+---------+--------+-----------+-----------+--------------+
| 1 | 1 | 1 | NULL | NULL |
+---------+--------+-----------+-----------+--------------+
1 row in set, 2 warnings (0.00 sec)1
2
3
4
5
6
7#查询基本薪资不在9000-12000之间的员工编号和基本薪资
SELECT employee_id,salary FROM employees
WHERE NOT (salary >= 9000 AND salary <= 12000);
SELECT employee_id,salary FROM employees
WHERE salary <9000 OR salary > 12000;
SELECT employee_id,salary FROM employees
WHERE salary NOT BETWEEN 9000 AND 12000;1
2
3
4SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary >= 10000
OR job_id LIKE '%MAN%';注意:
OR可以和AND一起使用,但是在使用时要注意两者的优先级,由于AND的优先级高于OR,因此先
对AND两边的操作数进行操作,再与OR中的操作数结合。
逻辑异或运算符
逻辑异或(XOR)运算符是
- 当给定的值中任意一个值为NULL时,则返回NULL;
- 如果两个非NULL的值都是0或者都不等于0时,则返回0;
- 如果一个值为0,另一个值不为0时,则返回1。
1
2
3
4
5
6
7mysql> SELECT 1 XOR -1, 1 XOR 0, 0 XOR 0, 1 XOR NULL, 1 XOR 1 XOR 1, 0 XOR 0 XOR 0;
+----------+---------+---------+------------+---------------+---------------+
| 1 XOR -1 | 1 XOR 0 | 0 XOR 0 | 1 XOR NULL | 1 XOR 1 XOR 1 | 0 XOR 0 XOR 0 |
+----------+---------+---------+------------+---------------+---------------+
| 0 | 1 | 0 | NULL | 1 | 0 |
+----------+---------+---------+------------+---------------+---------------+
1 row in set (0.00 sec)1
2
3select last_name,department_id,salary
from employees
where department_id in (10,20) XOR salary > 8000;
位运算符
位运算符是在二进制数上进行计算的运算符。位运算符会先将操作数变成二进制数,然后进行位运算,
最后将计算结果从二进制变回十进制数。
MySQL支持的位运算符如下:

按位与运算符
按位与(&)运算符将给定值对应的二进制数逐位进行逻辑与运算。
当给定值对应的二进制位的数值都为1时,则该位返回1,否则返回0。
1 | mysql> SELECT 1 & 10, 20 & 30; |
1的二进制数为0001,10的二进制数为1010,所以1 & 10的结果为0000,对应的十进制数为0。
20的二进制数为10100,30的二进制数为11110,所以20 & 30的结果为10100,对应的十进制数为20。
按位或运算符
按位或(|)运算符将给定的值对应的二进制数逐位进行逻辑或运算。
当给定值对应的二进制位的数值有一个或两个为1时,则该位返回1,否则返回0。
1 | mysql> SELECT 1 | 10, 20 | 30; |
1的二进制数为0001,10的二进制数为1010,所以1 | 10的结果为1011,对应的十进制数为11。
20的二进制数为10100,30的二进制数为11110,所以20 | 30的结果为11110,对应的十进制数为30。
按位异或运算符
按位异或(^)运算符将给定的值对应的二进制数逐位进行逻辑异或运算。
当给定值对应的二进制位的数值不同时,则该位返回1,否则返回0。
1 | mysql> SELECT 1 ^ 10, 20 ^ 30; |
1的二进制数为0001,10的二进制数为1010,所以1 ^ 10的结果为1011,对应的十进制数为11。
20的二进制数为10100,30的二进制数为11110,所以20 ^ 30的结果为01010,对应的十进制数为10。
按位取反运算符
按位取反(~)运算符将给定的值的二进制数逐位进行取反操作,即将1变为0,将0变为1。
1 | mysql> SELECT 10 & ~1; |
由于按位取反(~)运算符的优先级高于按位与(&)运算符的优先级,所以10 & ~1,首先,对数字1进行按位取反操作,结果除了最低位为0,其他位都为1,然后与10进行按位与操作,结果为10。
按位右移运算符
按位右移(>>)运算符将给定的值的二进制数的所有位右移指定的位数。
右移指定的位数后,右边低位的数值被移出并丢弃,左边高位空出的位置用0补齐。
1 | mysql> SELECT 1 >> 2, 4 >> 2; |
1的二进制数为0000 0001,右移2位为0000 0000,对应的十进制数为0。
4的二进制数为0000 0100,右移2位为0000 0001,对应的十进制数为1。
按位左移运算符
按位左移(<<)运算符将给定的值的二进制数的所有位左移指定的位数。
左移指定的位数后,左边高位的数值被移出并丢弃,右边低位空出的位置用0补齐。
1 | mysql> SELECT 1 << 2, 4 << 2; |
1的二进制数为0000 0001,左移两位为0000 0100,对应的十进制数为4。
4的二进制数为0000 0100,左移两位为0001 0000,对应的十进制数为16。
运算符的优先级

排序与分页
排序数据
排序规则
使用 ORDER BY 子句排序
ASC(ascend): 升序
DESC(descend):降序
ORDER BY 子句在SELECT语句的结尾。
单列排序
1 | SELECT last_name, job_id, department_id, hire_date |
多列排序
1 | SELECT last_name, department_id, salary |
- 可以使用不在SELECT列表中的列排序。
- 在对多列进行排序的时候,首先排序的第一列必须有相同的列值,才会对第二列进行排序。如果第一列数据中所有值都是唯一的,将不再对第二列进行排序。
分页
背景
- 查询返回的记录太多了,查看起来很不方便,使用分页查询
- 表里有 4 条数据,只显示第 2、3 条数据
实现
MySQL中使用 LIMIT 实现分页
格式:
1 | LIMIT [位置偏移量,] 行数 |
第一个“位置偏移量”参数指示MySQL从哪一行开始显示,是一个可选参数,如果不指定“位置偏移量”,将会从表中的第一条记录开始(第一条记录的位置偏移量是0,第二条记录的位置偏移量是1,以此类推);
第二个参数“行数”指示返回的记录条数。
1 | --前10条记录: |
分页显式公式:(当前页数-1)*每页条数,每页条数
1 | SELECT * FROM table |
注意:LIMIT 子句必须放在整个SELECT语句的最后!
- 使用 LIMIT 的好处
约束返回结果的数量可以减少数据表的网络传输量,也可以提升查询效率。
如果我们知道返回结果只有1 条,就可以使用LIMIT 1 ,告诉 SELECT 语句只需要返回一条记录即可。这样的好处就是SELECT 不需要扫描完整的表,只需要检索到一条符合条件的记录即可返回。
LIMIT在其他数据库中用其他关键词
- 在 MySQL、PostgreSQL、MariaDB 和 SQLite 中使用 LIMIT 关键字,而且需要放到 SELECT 语句的最后面。
- 如果是 SQL Server 和 Access,需要使用 TOP 关键字,比如:
SELECT TOP 5 name, hp_max FROM heros ORDER BY hp_max DESC
- 如果是 DB2,使用 FETCH FIRST 5 ROWS ONLY 这样的关键字:
SELECT name, hp_max FROM heros ORDER BY hp_max DESC FETCH FIRST 5 ROWS ONLY
- 如果是 Oracle,你需要基于 ROWNUM 来统计行数:
SELECT rownum,last_name,salary FROM employees WHERE rownum < 5 ORDER BY salary DESC;
多表查询
多表查询,也称为关联查询,指两个或更多个表一起完成查询操作。
前提条件:这些一起查询的表之间是有关系的(一对一、一对多),它们之间一定是有关联字段,这个关联字段可能建立了外键,也可能没有建立外键。比如:员工表和部门表,这两个表依靠“部门编号”进行关联。
等值连接
表的别名
- 使用别名可以简化查询。
- 列名前使用表名前缀可以提高查询效率。
1 | SELECT employees.last_name, departments.department_name,employees.department_id |
使用别名:
1 | SELECT e.employee_id, e.last_name, e.department_id, |
如果我们使用了表的别名,在查询字段中、过滤条件中就只能使用别名进行代替,不能使用原有的表名,否则就会报错。
非等值连接
查找条件为employees表中的工资在job_grades表中最高工资和最低工资之间的
1 | SELECT e.last_name, e.salary, j.grade_level |
自连接
表里可以通过一条信息的某个字段查到表里另一条信息
1 | SELECT worker.last_name , manager.last_name |
非自连接
连别的表
内连接
合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
外连接
两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。
- 如果是左外连接,则连接条件中左边的表也称为 主表 ,右边的表称为 从表 。
- 如果是右外连接,则连接条件中右边的表也称为 主表 ,左边的表称为 从表 。
内连接就是两个圆的交集,
左外连接就是交集+左表没在里面的部分,
右外连接就是交集+左表没在里面的部分
SQL92语法外连接(+)
左或右外连接中,(+) 表示哪个是从表。
Oracle 对 SQL92 支持较好,而 MySQL 则不支持 SQL92 的外连接。而且在 SQL92 中,只有左外连接和右外连接,没有满(或全)外连接。
1 | #左外连接 |
SQL99实现多表查询
使用JOIN…ON子句创建连接
内连接
INNER JOIN 可以省略 INNER
1
2
3
4SELECT e.employee_id, e.last_name, e.department_id,
d.department_id, d.location_id
FROM employees e JOIN departments d # 只有两个表
ON e.department_id = d.department_id;1
2
3
4
5
6SELECT employee_id, city, department_name
FROM employees e
JOIN departments d
ON d.department_id = e.department_id
JOIN locations l # 大于两个表就继续join
ON d.location_id = l.location_id;外连接
LEFT/RIGHT OUTER JOIN 可以省略 OUTER
1
2
3
4
5
6
7
8
9
10#左外连接
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
LEFT OUTER JOIN departments d
ON e.department_id = d.department_id ;
#右外连接
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
RIGHT OUTER JOIN departments d
ON (e.department_id = d.department_id) ;
满外连接
满外连接的结果 = 左右表匹配的数据 + 左表没有匹配到的数据 + 右表没有匹配到的数据。
SQL99是支持满外连接的。使用FULL JOIN 或 FULL OUTER JOIN来实现。
需要注意的是,MySQL不支持FULL JOIN(oracle支持),但是可以用 LEFT JOIN UNION RIGHT join代替。
UNION
合并查询结果
合并时,两个表对应的列数和数据类型必须相同,并且相互对应。
UNION操作符
UNION 操作符返回两个查询的结果集的并集,去除重复记录。
UNION ALL操作符
UNION ALL操作符返回两个查询的结果集的并集。对于两个结果集的重复部分,不去重。
尽量使用UNION ALL语句,以提高数据查询的效率。
可以用(左表非交集加交集)和(右表非交集)UNION ALL实现UNION的效果
7种SQL JOINS的实现
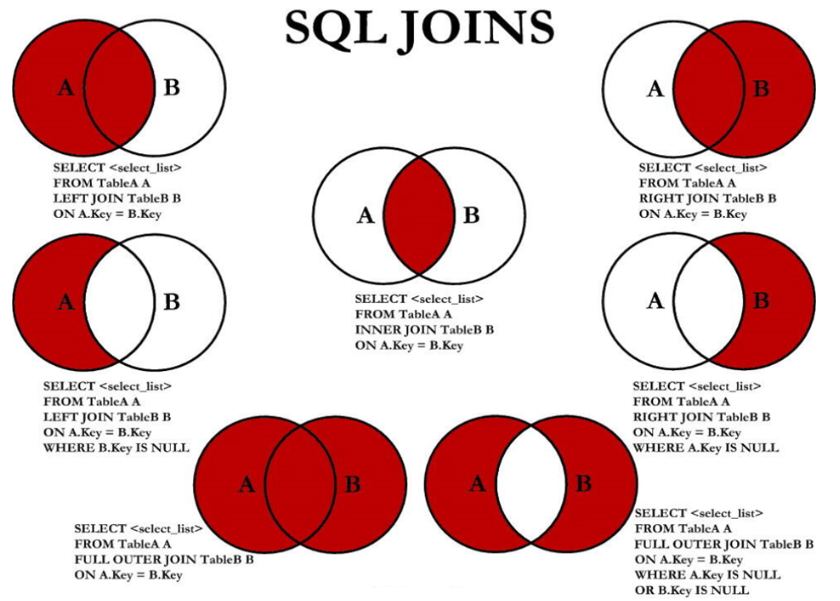
1 | #中图:内连接 A∩B |
using
当进行连接的时候,SQL99还支持使用 USING 指定数据表里的 同名字段 进行等值连接。但是只能配
合JOIN一起使用。
相当于JOIN…ON…换成JOIN…USING,USING后面只要写一个同名的等值就行
比如:
1 | SELECT employee_id,last_name,department_name |
单行函数
数值函数
基本函数

1 | SELECT |
角度与弧度互换函数
- 将角度转化为弧度,其中,参数x为角度值
RADIANS(x)
- 将弧度转化为角度,其中,参数x为弧度值
DEGREES(x)
1 | SELECT RADIANS(30),RADIANS(60),RADIANS(90),DEGREES(2*PI()),DEGREES(RADIANS(90)) |
三角函数

1 | SELECT |
指数与对数

1 | -> FROM DUAL; |
进制间的转换

1 | mysql> SELECT BIN(10),HEX(10),OCT(10),CONV(10,2,8) |
字符串函数


1 | mysql> SELECT FIELD('mm','hello','msm','amma'),FIND_IN_SET('mm','hello,mm,amma') |
1 | mysql> SELECT NULLIF('mysql','mysql'),NULLIF('mysql', ''); |
注意:MySQL中,字符串的位置是从1开始的。
日期和时间函数

1 | SELECT |
流程控制函数

1 | SELECT IF(1 > 0,'正确','错误') |
1 | SELECT IFNULL(null,'Hello Word') |
1 | SELECT CASE |
1 | SELECT CASE 1 |
1 | SELECT employee_id,salary, CASE WHEN salary>=15000 THEN '高薪' |
1 | SELECT oid,`status`, CASE `status` WHEN 1 THEN '未付款' |
1 | SELECT employee_id,12 * salary * (1 + IFNULL(commission_pct,0)) |
加密与解密函数

1 | mysql> SELECT PASSWORD('mysql'), PASSWORD(NULL); |
1 | SELECT md5('123') |
1 | SELECT SHA('Tom123') |
1 | mysql> SELECT ENCODE('mysql', 'mysql'); |
MySQL信息函数
MySQL中内置了一些可以查询MySQL信息的函数,这些函数主要用于帮助数据库开发或运维人员更好地
对数据库进行维护工作。

1 | mysql> SELECT DATABASE(); |
1 | mysql> SELECT USER(), CURRENT_USER(), SYSTEM_USER(),SESSION_USER(); |
1 | mysql> SELECT CHARSET('ABC'); |
1 | mysql> SELECT COLLATION('ABC'); |
聚合函数
聚合函数作用于一组数据,并对一组数据返回一个值。
聚合函数类型
- AVG()
- SUM()
- MAX()
- MIN()
- COUNT()
AVG和SUM函数
可以对数值型数据使用AVG 和 SUM 函数。
1 | SELECT AVG(salary), MAX(salary),MIN(salary), SUM(salary) |
MIN和MAX函数
可以对任意数据类型的数据使用 MIN 和 MAX 函数。
1 | SELECT MIN(hire_date), MAX(hire_date) |
COUNT函数
- COUNT(*)返回表中记录总数,适用于任意数据类型。
1
2
3SELECT COUNT(*)
FROM employees
WHERE department_id = 50; - COUNT(expr) 返回expr不为空的记录总数。
1
2
3ELECT COUNT(commission_pct)
FROM employees
WHERE department_id = 50;
group by
可以使用GROUP BY子句将表中的数据分成若干组
1 | SELECT AVG(salary) |
GROUP BY中使用WITH ROLLUP
使用 WITH ROLLUP 关键字之后,在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的总和,即统计记录数量。
1 | SELECT department_id,AVG(salary) |
注意:
当使用ROLLUP时,不能同时使用ORDER BY子句进行结果排序,即ROLLUP和ORDER BY是互相排斥
的。
HAVING
HAVING 不能单独使用,必须要跟 GROUP BY 一起使用。
1 | SELECT department_id, MAX(salary) |
WHERE 可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;
HAVING 必须要与 GROUP BY 配合使用,可以把分组计算的函数和分组字段作为筛选条件。WHERE 是先筛选后连接,而 HAVING 是先连接后筛选。
子查询
子查询指一个查询语句嵌套在另一个查询语句内部的查询
1 | #方式一: |
创建和管理表
数据类型

常用的几类类型介绍如下:

在定义数据类型时,如果确定是
整数,就用INT; 如果是小数,一定用定点数类型DECIMAL(M,D); 如果是日期与时间,就用DATETIME。
这样做的好处是,首先确保你的系统不会因为数据类型定义出错。不过,凡事都是有两面的,可靠性好,并不意味着高效。比如,TEXT虽然使用方便,但是效率不如CHAR(M)和VARCHAR(M)。
哪些情况使用 CHAR 或 VARCHAR 更好
- 情况1:存储很短的信息。比如门牌号码101,201……这样很短的信息应该用char,因为varchar还要占个byte用于存储信息长度,本来打算节约存储的,结果得不偿失。
- 情况2:固定长度的。比如使用uuid作为主键,那用char应该更合适。因为他固定长度,varchar动态根据长度的特性就消失了,而且还要占个长度信息。
- 情况3:十分频繁改变的column。因为varchar每次存储都要有额外的计算,得到长度等工作,如果一个非常频繁改变的,那就要有很多的精力用于计算,而这些对于char来说是不需要的。
创建数据库
- 创建数据库
1
CREATE DATABASE 数据库名;
- 创建数据库并指定字符集
1
CREATE DATABASE 数据库名 CHARACTER SET 字符集;
- 判断数据库是否已经存在,不存在则创建数据库( 推荐 )如果MySQL中已经存在相关的数据库,则忽略创建语句,不再创建数据库。
1
CREATE DATABASE IF NOT EXISTS 数据库名;
注意:DATABASE 不能改名。一些可视化工具可以改名,它是建新库,把所有表复制到新库,再删旧库完成的。
使用数据库
- 查看当前所有的数据库
1
SHOW DATABASES; #有一个S,代表多个数据库
- 查看当前正在使用的数据库
1
SELECT DATABASE(); #使用的一个 mysql 中的全局函数
- 查看指定库下所有的表
1
SHOW TABLES FROM 数据库名;
- 查看数据库的创建信息
1
2
3SHOW CREATE DATABASE 数据库名;
或者:
SHOW CREATE DATABASE 数据库名\G - 使用/切换数据库
1
USE 数据库名;
注意:要操作表格和数据之前必须先说明是对哪个数据库进行操作,否则就要对所有对象加上“数
据库名.”。
修改数据库
- 更改数据库字符集
1
ALTER DATABASE 数据库名 CHARACTER SET 字符集; #比如:gbk、utf8等
删除数据库
- 方式1:删除指定的数据库
1
DROP DATABASE 数据库名;
- 方式2:删除指定的数据库( 推荐 )
1
DROP DATABASE IF EXISTS 数据库名;
创建表
1 | CREATE TABLE [IF NOT EXISTS] 表名( |
必须指定:
表名
列名(或字段名),数据类型,长度可选指定:
约束条件
默认值
1 | -- 创建表 |
1 | CREATE TABLE dept( |
修改表
修改表指的是修改数据库中已经存在的数据表的结构。
使用 ALTER TABLE 语句可以实现:
- 向已有的表中添加列
- 修改现有表中的列
- 删除现有表中的列
- 重命名现有表中的列
追加一个列
语法格式如下:
1 | ALTER TABLE 表名 ADD 【COLUMN】 字段名 字段类型 【FIRST|AFTER 字段名】; |
举例:
1 | ALTER TABLE dept80 |
修改一个列
- 可以修改列的数据类型,长度、默认值和位置
- 修改字段数据类型、长度、默认值、位置的语法格式如下:举例:
1
2ALTER TABLE 表名 MODIFY 【COLUMN】 字段名1 字段类型 【DEFAULT 默认值】【FIRST|AFTER 字段名
2】;1
2ALTER TABLE dept80
MODIFY last_name VARCHAR(30)1
2ALTER TABLE dept80
MODIFY salary double(9,2) default 1000;
重命名一个列
使用 CHANGE old_column new_column dataType子句重命名列。语法格式如下:
1 | ALTER TABLE 表名 CHANGE 【column】 列名 新列名 新数据类型; |
举例:
1 | ALTER TABLE dept80 |
删除一个列
删除表中某个字段的语法格式如下:
1 | ALTER TABLE 表名 DROP 【COLUMN】字段名 |
举例:
1 | ALTER TABLE dept80 |
重命名表
- 方式一:使用RENAME
1
2RENAME TABLE emp
TO myemp - 方式二:
1
2ALTER table dept
RENAME [TO] detail_dept; -- [TO]可以省略
删除表
在MySQL中,当一张数据表 没有与其他任何数据表形成关联关系 时,可以将当前数据表直接删除。
语法格式:
1 | DROP TABLE [IF EXISTS] 数据表1 [, 数据表2, …, 数据表n]; |
IF EXISTS 的含义为:如果当前数据库中存在相应的数据表,则删除数据表;
如果当前数据库中不存在相应的数据表,则忽略删除语句,不再执行删除数据表的操作。
清空表
TRUNCATE TABLE语句:
- 删除表中所有的数据
- 释放表的存储空间
举例:
1 | TRUNCATE TABLE detail_dept; |
TRUNCATE语句不能回滚,而使用 DELETE 语句删除数据,可以回滚
1 | DELETE FROM emp2; |
数据处理之增删改
插入数据
使用 INSERT 语句向表中插入数据。
方式1:VALUES的方式添加
使用这种语法一次只能向表中插入一条数据。
值列表中需要为表的每一个字段指定值,并且值的顺序必须和数据表中字段定义时的顺序相同。
VALUES 也可以写成 VALUE ,但是VALUES是标准写法。
字符和日期型数据应包含在单引号中。
- 按默认顺序插入数据
1
2NSERT INTO departments
VALUES (70, 'Pub', 100, 1700); - 为表的指定字段插入数据
1
2INSERT INTO departments(department_id, department_name)
VALUES (80, 'IT');# 其他字段的值为表定义时的默认值。 - 同时插入多条记录
1
2
3
4
5INSERT INTO emp(emp_id,emp_name)
VALUES
(1001,'shkstart'),
(1002,'atguigu'),
(1003,'Tom');
方式2:将查询结果插入到表中
INSERT可以将SELECT语句查询的结果插入到表中
1 | INSERT INTO emp2 |
1 | INSERT INTO sales_reps(id, name, salary, commission_pct) |
更新数据
使用 UPDATE 语句更新数据。
如果需要回滚数据,需要保证在DML前,进行设置:SET AUTOCOMMIT = FALSE;
1 | UPDATE employees |
删除数据
使用 DELETE 语句从表中删除数据
1 | DELETE FROM departments |
约束
约束是表级的强制规定。
- 可以在创建表时规定约束(通过 CREATE TABLE 语句),
- 或者在表创建之后通过 ALTER TABLE 语句规定约束。
根据约束起的作用,约束可分为:
- NOT NULL 非空约束,规定某个字段不能为空
- UNIQUE 唯一约束,规定某个字段在整个表中是唯一的
- PRIMARY KEY 主键(非空且唯一)约束
- FOREIGN KEY 外键约束
- CHECK 检查约束
- DEFAULT 默认值约束
注意: MySQL不支持check约束,但可以使用check约束,而没有任何效果
查看某个表已有的约束
1 | #information_schema数据库名(系统库) |
非空约束
限定某个字段/某列的值不允许为空
NOT NULL
添加非空约束
建表时
1
2
3
4
5CREATE TABLE 表名称(
字段名 数据类型,
字段名 数据类型 NOT NULL,
字段名 数据类型 NOT NULL
);举例:
1
2
3
4
5CREATE TABLE emp(
id INT(10) NOT NULL,
NAME VARCHAR(20) NOT NULL,
sex CHAR NULL
);建表后
1
alter table 表名称 modify 字段名 数据类型 not null;
举例:
1
2ALTER TABLE emp
MODIFY sex VARCHAR(30) NOT NULL
删除非空约束
1 | lter table 表名称 modify 字段名 数据类型 NULL;#去掉not null,相当于修改某个非注解字段,该字段允许为空 |
举例:
1 | ALTER TABLE emp |
唯一性约束
用来限制某个字段/某列的值不能重复。
UNIQUE
添加唯一约束
建表时
1
2
3
4
5
6create table 表名称(
字段名 数据类型,
字段名 数据类型 unique,
字段名 数据类型 unique key, #unique和unique key效果一样
字段名 数据类型
);举例:
1
2
3
4
5
6create table student(
sid int,
sname varchar(20),
tel char(11) unique,
cardid char(18) unique key
);建表后指定唯一键约束
1
2#方式1:
alter table 表名称 add unique key(字段列表);1
2#方式2:
alter table 表名称 modify 字段名 字段类型 unique;举例:
1
2ALTER TABLE USER
ADD UNIQUE(NAME,PASSWORD);1
2ALTER TABLE USER
MODIFY NAME VARCHAR(20) UNIQUE;
删除唯一约束
1 | SELECT * FROM information_schema.table_constraints WHERE table_name = '表名'; #查看都有哪些约束 |
1 | ALTER TABLE table_name |
PRIMARY KEY 约束
主键约束相当于唯一约束+非空约束的组合,主键约束列不允许重复,也不允许出现空值。
一个表最多只能有一个主键约束
当创建主键约束时,系统默认会在所在的列或列组合上建立对应的主键索引。如果删除主键约束了,主键约束对应的索引就自动删除了
主键(PRIMARY KEY)和唯一键(UNIQUE KEY)的区别
- 主键:通常不允许NULL值,除非特别指定列可以包含NULL。
唯一键:可以包含NULL值,但每个NULL值只允许出现一次。 - 主键:在一个表中只能有一个主键。
唯一键:可以有多个唯一键。 - 主键:经常被用作其他表中外键约束的引用。
唯一键:也可以作为外键的引用,但更常见的是主键被用作外键的引用。
添加主键约束
- 建表时指定主键约束举例:
1
2
3
4
5create table 表名称(
字段名 数据类型 primary key, #列级模式
字段名 数据类型,
字段名 数据类型
);1
2
3
4create table temp(
id int primary key,
name varchar(20)
); - 建表后增加主键约束举例:
1
ALTER TABLE 表名称 ADD PRIMARY KEY(字段列表); #字段列表可以是一个字段,也可以是多个字段,如果是多个字段的话,是复合主键
1
ALTER TABLE student ADD PRIMARY KEY (sid);
复合主键
像账户、密码可以做成复合主键
1 | create table 表名称( |
举例:
1 | create table student_course( |
1 | CREATE TABLE emp6( |
删除主键约束
1 | alter table 表名称 drop primary key; |
举例:
1 | ALTER TABLE student DROP PRIMARY KEY; |
说明:删除主键约束,不需要指定主键名,因为一个表只有一个主键,删除主键约束后,非空还存
在。
自增列:AUTO_INCREMENT
某个字段的值自增
auto_increment
- 一个表最多只能有一个自增长列
- 自增长列约束的列必须是键列(主键列,唯一键列)
- 自增约束的列的数据类型必须是整数类型
如何指定自增约束
- 建表时举例:
1
2
3
4
5
6
7
8
9
10
11
12create table 表名称(
字段名 数据类型 primary key auto_increment,
字段名 数据类型 unique key not null,
字段名 数据类型 unique key,
字段名 数据类型 not null default 默认值,
);
create table 表名称(
字段名 数据类型 default 默认值 ,
字段名 数据类型 unique key auto_increment,
字段名 数据类型 not null default 默认值,,
primary key(字段名)
);1
2
3
4create table employee(
eid int primary key auto_increment,
ename varchar(20)
); - 建表后举例:
1
alter table 表名称 modify 字段名 数据类型 auto_increment;
1
alter table employee modify eid int auto_increment;
如何删除自增约束
1 | #alter table 表名称 modify 字段名 数据类型 auto_increment;#给这个字段增加自增约束 |
举例:
1 | alter table employee modify eid int; |
FOREIGN KEY 约束
限定某个表的某个字段的引用完整性。
比如:员工表的员工所在部门的选择,必须在部门表能找到对应的部分。
外键约束可以保证当主键表中的数据被更新或删除时,相关的外键表中的数据也会相应地更新或删除,以保持数据的一致性。
主表和从表/父表和子表
主表(父表):被引用的表,被参考的表
从表(子表):引用别人的表,参考别人的表
例如:员工表的员工所在部门这个字段的值要参考部门表:部门表是主表,员工表是从表。
- 删表时,先删从表(或先删除外键约束),再删除主表
- 当主表的记录被从表参照时,主表的记录将不允许删除,如果要删除数据,需要先删除从表中依赖该记录的数据,然后才可以删除主表的数据
- 在“从表”中指定外键约束,并且一个表可以建立多个外键约束
- 删除外键约束后,必须
手动删除对应的索引
添加外键约束
建表时
1
2
3
4
5
6
7
8
9
10
11
12
13create table 主表名称(
字段1 数据类型 primary key,
字段2 数据类型
);
create table 从表名称(
字段1 数据类型 primary key,
字段2 数据类型,
[CONSTRAINT <外键约束名称>] FOREIGN KEY(从表的某个字段) references 主表名(被参考字段)
);
#(从表的某个字段)的数据类型必须与主表名(被参考字段)的数据类型一致,逻辑意义也一样
#(从表的某个字段)的字段名可以与主表名(被参考字段)的字段名一样,也可以不一样
-- FOREIGN KEY: 在表级指定子表中的列
-- REFERENCES: 标示在父表中的列举例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14create table dept( #主表
did int primary key, #部门编号
dname varchar(50) #部门名称
);
create table emp(#从表
eid int primary key, #员工编号
ename varchar(5), #员工姓名
deptid int, #员工所在的部门
foreign key (deptid) references dept(did) #在从表中指定外键约束
#emp表的deptid和和dept表的did的数据类型一致,意义都是表示部门的编号
);
说明:
(1)主表dept必须先创建成功,然后才能创建emp表,指定外键成功。
(2)删除表时,先删除从表emp,再删除主表dept和primary key可以直接写在定义的字段后面不同
foreign key外键约束必须在列定义之后单独声明
而primary key既可以在列定义时直接声明,也可以在所有列定义之后作为一个单独的约束声明建表后
1
ALTER TABLE 从表名 ADD [CONSTRAINT 约束名] FOREIGN KEY (从表的字段) REFERENCES 主表名(被引用字段) [on update xx][on delete xx];
举例:
1
2
3
4
5
6
7
8
9
10create table dept(
did int primary key, #部门编号
dname varchar(50) #部门名称
);
create table emp(
eid int primary key, #员工编号
ename varchar(5), #员工姓名
deptid int #员工所在的部门
);
#这两个表创建时,没有指定外键的话,那么创建顺序是随意1
alter table emp add foreign key (deptid) references dept(did);
删除外键约束
1 | (1)第一步先查看约束名和删除外键约束 |
举例:
1 | SELECT * FROM information_schema.table_constraints WHERE table_name = 'emp'; |
删主键自动删索引,删外键还得手动删
如果两个表之间有关系(一对一、一对多),比如:员工表和部门表(一对多),它们之间是否
一定要建外键约束?
不是的
建和不建外键约束有什么区别?
建外键约束,操作(创建表、删除表、添加、修改、删除)会受到限制
建和不建外键约束和查询有没有关系?
没有
CHECK 约束
检查某个字段的值是否符号xx要求,一般指的是值的范围
1 | CREATE TABLE temp( |
1 | age tinyint check(age >20) 或 sex char(2) check(sex in(‘男’,’女’)) |
1 | CHECK(height>=0 AND height<3) |
MySQL 5.7 不支持,MySQL 8.0中可以使用check约束。
DEFAULT约束
给某个字段/某列指定默认值,一旦设置默认值,在插入数据时,如果此字段没有显式赋值,则赋值为默认值。
如何给字段加默认值
- 建表时举例:
1
2
3
4
5
6
7
8create table 表名称(
字段名 数据类型 default 默认值 ,
字段名 数据类型 not null default 默认值,
字段名 数据类型 not null default 默认值,
primary key(字段名),
unique key(字段名)
);
说明:默认值约束一般不在唯一键和主键列上加1
2
3
4
5
6create table employee(
eid int primary key,
ename varchar(20) not null,
gender char default '男',
tel char(11) not null default '' #默认是空字符串
); - 建表后举例:
1
2
3
4alter table 表名称 modify 字段名 数据类型 default 默认值;
#如果这个字段原来有非空约束,你还保留非空约束,那么在加默认值约束时,还得保留非空约束,否则非空约束就被删除了
#同理,在给某个字段加非空约束也一样,如果这个字段原来有默认值约束,你想保留,也要在modify语句中保留默认值约束,否则就删除了
alter table 表名称 modify 字段名 数据类型 default 默认值 not null;1
alter table employee modify tel char(11) default '' not null;#给tel字段增加默认值约束,并保留非空约束
如何删除默认值约束
1 | alter table 表名称 modify 字段名 数据类型 ;#删除默认值约束,也不保留非空约束 |
举例:
1 | alter table employee modify gender char; #删除gender字段默认值约束,如果有非空约束,也一并删除 |
为什么不想要 null 的值
- 不好比较。null是一种特殊值,比较时只能用专门的is null 和 is not null来比较。碰到运算符,通
常返回null。- 效率不高。影响提高索引效果。因此,我们往往在建表时 not null default ‘’ 或 default 0
带AUTO_INCREMENT约束的字段值是从1开始的吗?
在MySQL中,默认AUTO_INCREMENT的初始值是1,每新增一条记录,字段值自动加1。
`